Genetický kód: popis, vlastnosti, historie výzkumu
Každý živý organismus má speciální sadu bílkovin. Určité nukleotidové sloučeniny a jejich sekvence v DNA molekula tvoří genetický kód. Poskytuje informace o struktuře bílkovin. V genetice byla přijata určitá koncepce. Podle ní jeden enzym (polypeptid) odpovídá jednomu genu. Je třeba říci, že výzkum nukleových kyselin a bílkovin byl prováděn za poměrně dlouhou dobu. Dále v článku se budeme bližší podívat na genetický kód a jeho vlastnosti. Dále bude uvedena stručná chronologie výzkumu. 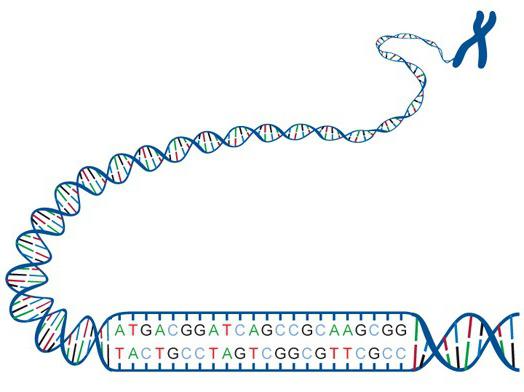
Terminologie
Genetický kód je způsob kódování sekvence aminokyselinových proteinů zahrnujících nukleotidovou sekvenci. Tato metoda tvorby informací je charakteristická pro všechny živé organismy. Proteiny jsou přirozeně se vyskytující organické látky s vysokou molekulovou hmotností. Tyto sloučeniny jsou také přítomny v živých organismech. Obsahují 20 typů aminokyselin, které se nazývají "kanonické". Aminokyseliny jsou uspořádány v řetězci a spojeny v přísně definované sekvenci. Definuje to proteinové struktury a jeho biologické vlastnosti. V proteinu je také několik řetězců aminokyselin. 
DNA a RNA
Deoxyribonukleová kyselina je makromolekula. Je odpovědná za přenos, ukládání a implementaci dědičných informací. DNA používá čtyři dusíkaté báze. Patří sem adenin, guanin, cytosin, thymin. RNA se skládá ze stejných nukleotidů, kromě těch, které obsahují tymin. Namísto toho existuje nukleotid obsahující uracil (U). RNA a molekuly DNA jsou nukleotidové řetězce. Kvůli této struktuře se tvoří sekvence - "genetická abeceda".
Ad
Implementace informací
Syntéza proteinů, který je kódován genem, je realizován kombinací mRNA na templátu DNA (transkripce). Také přenos genetického kódu v aminokyselinové sekvenci. To znamená, že existuje syntéza polypeptidového řetězce na mRNA. K šifrování všech aminokyselin a signalizaci konce proteinové sekvence je dostatečné 3 nukleotidy. Tento řetězec se nazývá triplet. 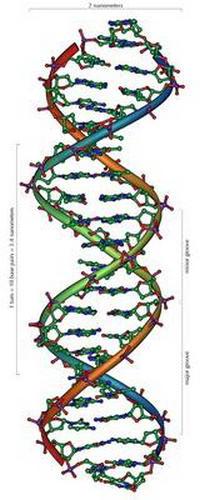
Historie výzkumu
Studium bílkovin a nukleových kyselin dlouhou dobu. V polovině 20. století se konečně objevily první myšlenky o povaze genetického kódu. V roce 1953 bylo zjištěno, že některé proteiny jsou složeny z aminokyselinových sekvencí. Je pravda, že dosud nemohli určit přesné číslo a v této záležitosti došlo k mnoha sporům. V roce 1953 byly publikovány dva články autorů Watson a Crick. První deklarovala sekundární strukturu DNA, druhá řekla o svém přípustném kopírování pomocí matricové syntézy. Kromě toho byl kladen důraz na skutečnost, že konkrétní sekvence základen je kód, který nese dědičná informace. Americký a sovětský fyzik Georgy Gamov povolil kódovací hypotézu a našel metodu pro jeho ověření. V roce 1954 byla publikována jeho práce, během níž předložil návrh na stanovení shody mezi postranními řetězci aminokyselin a "romboidními" otvory a použije je jako kódovací mechanismus. Pak byl nazván kosočtverečným. Gamow vysvětlil svou práci a připustil, že genetický kód může být trojčlenný. Fyzika práce byla jedním z prvních, kteří byli považováni za blízké pravdě. 
Klasifikace
Po několika letech byly navrženy různé modely genetických kódů, které představují dva typy: překrývající se a nepřekrývající se. Základem prvního byl vstup jednoho nukleotidu do několika kodonů. K tomu patří trojúhelníkový, sekvenční a hlavní drobný genetický kód. Druhý model zahrnuje dva typy. Nepřekrývají se kombinační a "bez čárků". První variant je založen na aminokyselinovém kódování nukleotidových tripletů a hlavní věc je jeho složení. Podle "kódu bez čárky", některé triplety odpovídají aminokyselinám a zbytek ne. V tomto případě bylo věřeno, že pokud by byly významně uspořádány nějaké významné triplety, ostatní by nebyly nutné v jiném čtecím rámci. Vědci věřili, že existuje možnost výběru nukleotidové sekvence, která splní tyto požadavky, a že existuje přesně 20 tripletů.  Ačkoli Gamow et al. Zpochybňoval tento model, byl považován za nejpřesnější pro příštích pět let. Na počátku druhé poloviny 20. století se objevily nové údaje, které odhalily některé nedostatky v "kódu bez čárkami". Bylo zjištěno, že kodony mohou provokovat syntézu proteinů in vitro. Ke konci roku 1965 byl pochopen princip všech 64 tripletů. V důsledku toho byla zjištěna redundance některých kodonů. Jinými slovy, aminokyselinová sekvence je kódována několika triplety.
Ačkoli Gamow et al. Zpochybňoval tento model, byl považován za nejpřesnější pro příštích pět let. Na počátku druhé poloviny 20. století se objevily nové údaje, které odhalily některé nedostatky v "kódu bez čárkami". Bylo zjištěno, že kodony mohou provokovat syntézu proteinů in vitro. Ke konci roku 1965 byl pochopen princip všech 64 tripletů. V důsledku toho byla zjištěna redundance některých kodonů. Jinými slovy, aminokyselinová sekvence je kódována několika triplety.
Výrazné vlastnosti
Vlastnosti genetického kódu zahrnují:
- Triplet. Sekvence tří nukleotidů je významnou jednotkou kódu.
- Kontinuita. Triplety nemají interpunkční znaménka existuje neustálé čtení informací.
- Překrývání. Nukleotid je součástí pouze jednoho tripletu. U některých genů virů, bakterií a mitochondrií je kódováno několik proteinů a dochází k čtení snímků.
- Jednoznačnost. Specifický kodon odpovídá ne více než jedné aminokyselině. Pravda, Euplotescrassus UGA může kódovat cystein a Silenocystein.
- Degenerace Specifická aminokyselina odpovídá několika kodonům.
- Všestrannost. Genetický kód funguje podle stejného principu v organismech s různou složitostí. To je podstatou genetického inženýrství. Existují však některé výjimky.
- Odolnost proti hluku. Mutační nukleotidové substituce jsou konzervativní a radikální. První nevede ke změně třídy kódované aminokyseliny. Radikální mutace mění třídu kódované aminokyseliny.
Variace
Poprvé byla odchylka genetického kódu od standardního odhalena v roce 1979 při studiu mitochondriálních genů v lidském těle. Dále byly identifikovány více podobných variant, včetně množství alternativních mitochondriálních kódů. Patří sem dekódování stop kodonu CAA, které se používá jako definice tryptofanu v mykoplazmech. GUG a CCG v archea a bakterie jsou často používány jako výchozí varianty. Někdy geny kódují protein z počátečního kodonu, který se liší od standardu používaného tímto druhem. Kromě toho v některých proteinech se do ribosomu vkládají selenocystein a pyrrolysin, což jsou nestandardní aminokyseliny. Přečte stop kodon. Záleží na sekvencích nalezených v mRNA. V současné době je selenocystein považován za 21., pyrolizan - 22. aminokyselina přítomná v složení bílkovin.
Společné rysy genetického kódu
Nicméně všechny výjimky jsou vzácné. V živých organismech má hlavně genetický kód řadu společných rysů. Patří sem složení kodonu, které zahrnuje tři nukleotidy (první dvě patří k rozhodujícímu), přenos tRNA kodonů a ribozomů v aminokyselinové sekvenci.