Soubor čtení: file get content function (PHP)
Formálně se soubor dostává do obsahu PHP konstrukce je podobná souboru, ale umístí čtený obsah do řetězce, nikoliv do pole řetězců, a umožňuje zadat posun v souboru, ze kterého chcete číst.
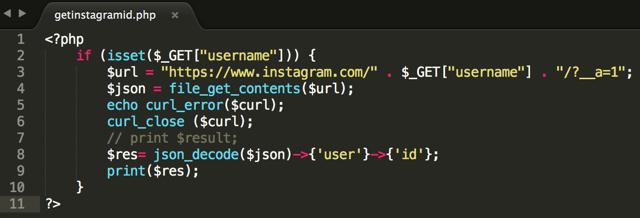
Pravidelné čtení fopen / fgets / fclose se stává méně relevantní. Je pohodlnější číst obsah celého souboru nebo stránky webu a pak s ním provést potřebné operace. Soubor PHP získává obsahovou konstrukci umožňuje vytvářet efektivnější a efektivnější algoritmy. zpracování informací.
Syntaxe a příklad použití
Syntaxe:

Zde $ název souboru je název souboru nebo adresa stránky, $ use_include_path umožňuje vyhledávat soubor v cestě zahrnutí, $ kontext je prostředek vytvořený konstruktem stream_context_create (), $ offset je offset pro čtení, $ maxlen je maximální množství dat, které se mají číst .
Ad
Jednodušší PHP soubor získat obsah je obvykle používán:
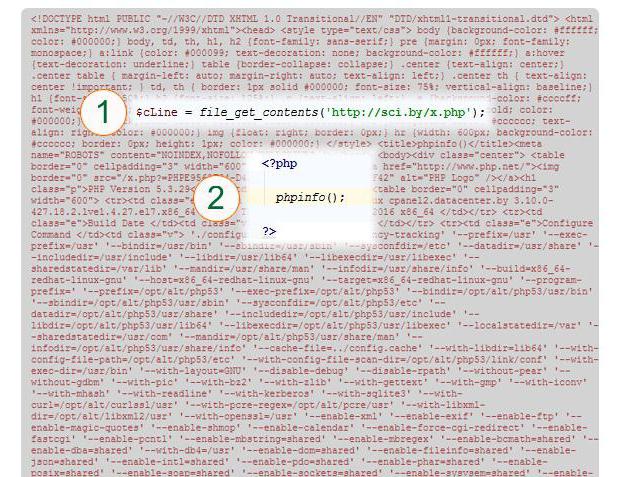 V tomto příkladu se obsah stránky přečte do proměnné $ cLine (1). Zadaná adresa URL je označena. Ve skutečnosti je stránka (2) reprezentována konstrukcí PHP phpinfo (), tj. Není to text tří čar, který je čten, ale výsledkem provedení této funkce.
V tomto příkladu se obsah stránky přečte do proměnné $ cLine (1). Zadaná adresa URL je označena. Ve skutečnosti je stránka (2) reprezentována konstrukcí PHP phpinfo (), tj. Není to text tří čar, který je čten, ale výsledkem provedení této funkce.
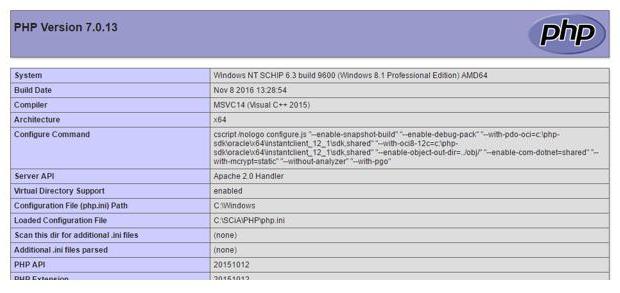
Jak vidíte, výsledkem je plnohodnotná stránka, zatímco soubor PHP získává konstrukci obsahu na (http ...) číst a psát vnitřní obsah této stránky v proměnné $ cLine.
Kontextové možnosti a možnosti
Je třeba mít na paměti, že použití kontextového parametru $ otevírá velké možnosti.

V běžné praxi není použití všech parametrů s výjimkou $ filename oblíbené pravidlo. Hodnota vytvořená konstruktem stream_context_create () a použitá jako kontextový parametr $ však umožňuje napsat docela složité algoritmy pro získání potřebných informací.
Ad
Různé systémy souborů, manipulátory toku (wrappers) vyžadují různé parametry a možnosti popisu kontextu. Může být vytvořen prostřednictvím konstrukcí stream_context_create (stream_context_set_option, stream_context_set_params).
Zpracování velkých stránek
Namísto konkrétního URL adresy Parametr $ filename může být reprezentován názvem proměnné. To umožňuje analyzovat obsah stránek v automatickém programovatelném režimu, rozpoznávat jména stránek, určovat odkazy a získávat potřebné informace.
Můžete si vytvořit vlastní analyzátor stránek, vyhledávač a psát programy pro distribuované zpracování informací. Úloha je relevantní, zajímavá a praktická.
Čtení textových souborů
Neexistují žádné problémy, které by se daly číst. V následující, složité verzi, soubor get content php konstrukce je příkladem toho, že soubor "Word" lze číst bez problémů:

Zde je složitý dokument, který se používá k otestování knihovny PHPOffice / PHPWord. Soubor MS Word (* .docx), jak víte, je zip-archiv, uvnitř kterého jsou informace o standardu Open XML.
Soubory dokumentů jsou zpravidla poměrně velké a složité, ale soubor PHP získává obsahové konstrukce a bez problémů je čte. Specifičnost tohoto konkrétního příkladu spočívá v tom, že zpracování dokumentu pomocí knihovny čistě PHPOffice / PHPWord neposkytuje potřebné funkce a je prostě nemožné číst soubor postupně.
Ad
V tomto dokumentu jsou všechny jeho prvky (slova, odstavce, vzorce, obrázky, pravopisné prvky) popsány řadou značek, z nichž některé mohou být reprezentovány sekvencí objektů vnořených do sebe.
Pokud použijete příklad dokumentu (* .docx) s tabulkami, není situace v sekvenčním zpracování souboru vůbec vyřešitelná. Vyžaduje nejméně dva průchody skrz tělo dokumentu, pokud se neřídí zejména, když se stoly hnízdí navzájem.
Kódování a speciální znakové problémy
Pokud čtete složité soubory, nevyvolává problémy, pak problémy s práci s jednoduchými soubory. Zpočátku by mělo být považováno za axiom: PHP čte soubor správně. Dokonce i když nepoužíváte určité parametry, nejjednodušší verze aplikace bude vždy pracovat správně.
Problémy jsou způsobeny úhlovými závorami a kódováním souborů. Je nutné rozlišovat práci uvnitř algoritmu od zobrazení výsledku v okně prohlížeče. Na obrázku s příkladem souboru Word řádek (1) - $ cLine = scChangeLTGT ($ cLine) - volá funkci převodu dvojice úhlových závorek do speciálních znaků "<" a ">", jinak se v okně prohlížeče nemusí vždy zobrazit pouze čtecí soubor. Jak psát tuto funkci není důležité, ale je důležité nezapomínat, že čtená informace mohou obsahovat tagy XML a HTML, což vyžaduje zvláštní pozornost.
Ad
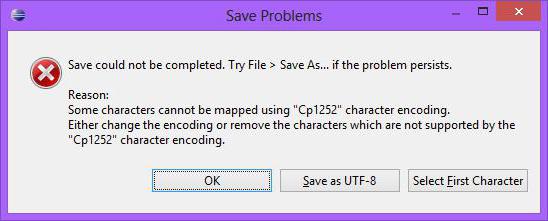
Další bod: kódování souborů. Ne vždy jednoduchý textový soubor nevytváří problémy. Pokud se čte textové informace, přítomnost ruských dopisů může způsobit určité potíže (2).
$ cLine = iconv ('UTF-8', 'CP1251', $ cLine). V tomto kontextu je použití funkce iconv () se správným směrem konverze relevantní nejen ve vztahu k PHP "file get content http://" pro čtení stránky webu, ale také při čtení obyčejného lokálního souboru.
Pokud je výsledek čtení "neviditelný", je třeba nejprve zkontrolovat kódování znaků.