Bez tabulky znaků Unicode
Unicode je mezinárodní standard pro kódování znaků, který vám umožňuje zobrazovat texty jednotně na libovolném počítači na světě bez ohledu na použitý systémový jazyk.
Základy
Abychom pochopili, proč je zapotřebí tabulka symbolů Unicode, nejprve se podívejme na mechanismus pro zobrazení textu na obrazovce monitoru. Počítač, jak víme, zpracovává všechny informace v digitální podobě a musí být zobrazen v grafické podobě pro správné vnímání osoby. Proto, abychom si mohli přečíst tento text, musíme vyřešit alespoň dva problémy:
- Zakódovat tisknutelné znaky v digitální podobě.
- Poskytněte operačnímu systému možnost přizpůsobit digitální formulář vektorovým symbolům, jinými slovy najít správná písmena.
První kódování
Předek všech zakódování je považován za amerického ASCII. Popisuje latinskou abecedu používanou v angličtině interpunkční znaménka a Arabské číslice. Bylo to použití 128 znaků, které se staly základem pro další vývoj - dokonce i moderní tabulka symbolů Unicode je používá. Písmena latinské abecedy od té doby obsadily první místo v jakémkoli kódování.

Celkově ASCII umožnilo uložit 256 znaků, ale protože první 128 bylo v latinkách, ostatní 128 začalo být používáno po celém světě k vytvoření národních standardů. Například v Rusku byly založeny CP866 a KOI8-R. Takové varianty byly nazývány rozšířenými verzemi ASCII.
Ad
Kódové stránky a crackdowns
Další vývoj technologie a vznik GUI vedl k tomu, že byl vytvořen americký institut normalizace, který kóduje ANSI. Pro ruské uživatele, obzvláště se zkušenostmi, je její verze známá jako Windows 1251. Poprvé byl použit koncept "kódová stránka". S pomocí kódových stránek, které obsahovaly symboly národních abeced, jiné než latinské, vzniklo "vzájemné porozumění" mezi počítači používanými v různých zemích.
Nicméně přítomnost velkého počtu různých kódování použitých pro jeden jazyk začala způsobovat problémy. Byly tam takzvané krakozyabry. Vznikly z nesouladu původní kódové stránky, ve které byly vytvořeny všechny informace, a kódová stránka byla ve výchozím nastavení použita na počítači koncového uživatele.
Ad

Jako příklad lze citovat výše uvedené cyrilské kódování CP866 a KOI8-R. Písmena v nich se lišily kódovými pozicemi a zásadami umístění. V první byly uspořádány v abecedním pořadí a ve druhém - v libovolném. Můžete si představit, co se dělo před očima uživatele, který se pokoušel o otevření takového textu, aniž by měl potřebnou kódovou stránku nebo byl nesprávně interpretován počítačem.
Vytvoření Unicode
Rozšiřování internetu a souvisejících technologií, jako je e-mail, vedlo k tomu, že nakonec situace s narušením textů přestala vyhovovat všem. Vedoucí IT společnosti vytvořily konsorcium Unicode ("Unicode Consortium"). Tabulka znaků, která jim byla předána v roce 1991 pod názvem UTF-32, umožnila uložit více než miliardu unikátních postav. To byl nejdůležitější krok na cestě k rozluštění textů.
Ad

První univerzální tabulka kódů znaků Unicode UTF-32 však nebyla široce používána. Hlavním důvodem byla redundance uložených informací. Rychle se počítala, že pro země, ve kterých je latinská abeceda kódovaný pomocí nového univerzálního stolu, text bude trvat čtyřnásobně větší prostor než při použití rozšířené tabulky ASCII.
Vývoj Unicode
Následující tabulka symbolů Unicode UTF-16 tento problém vyřešila. Kódování v něm bylo provedeno v polovině počtu bitů, ale současně počet možných kombinací klesl. Místo miliard čísel vám umožňuje ušetřit pouze 65 536. Nicméně bylo to tak úspěšné, že toto číslo bylo podle rozhodnutí konsorcia určeno jako základní znakový úložný prostor standardu Unicode.
Navzdory tomuto úspěchu nebyl UTF-16 vhodný pro všechny, protože množství uložených a přenášených informací bylo ještě dvakrát vyšší. Univerzálním řešením byla tabulka znaků Unicode s proměnnou délkou UTF-8. To může být nazýváno průlomem v této oblasti.

Proto se zavedením posledních dvou standardů tabulka symbolů Unicode vyřešila problém jediného kódového prostoru pro všechna aktuálně používaná písma.
Unicode pro ruský jazyk
Vzhledem k proměnné délce kódu používaného k zobrazení znaků je latinka kódována v Unicode stejným způsobem jako ve svém progenitoru ASCII, tedy v jednom bitu. Pro jiné abecedy může vypadat obrázek jinak. Například znaky gruzínské abecedy se používají pro kódování tří bajtů a znamení azbuky - dvě. To vše je možné v rámci používání standardu Unicode UTF-8 (tabulka symbolů). Ruský jazyk nebo azylová abeceda zaujímá 448 pozic v obecném kódovém prostoru rozděleném do pěti bloků.
Ad
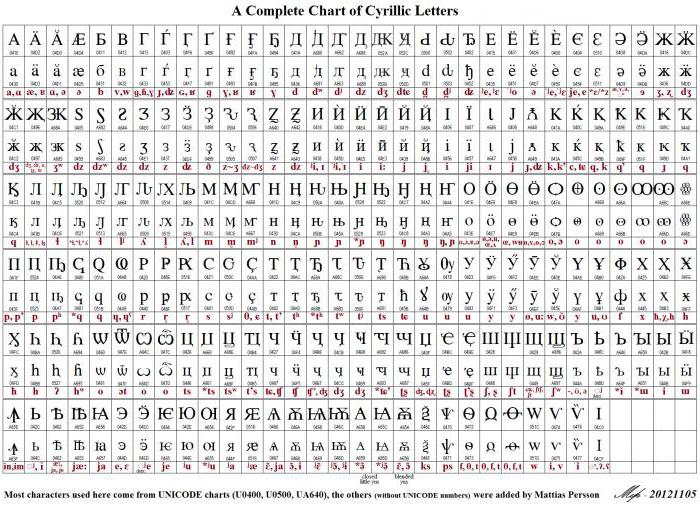
K těmto pěti blokům patří hlavní cyrilská a církevní slovanská abeceda, stejně jako další písmena jiných jazyků pomocí cyrilika. Počet pozic je zvýrazněn, aby se zobrazily staré formy zobrazení cyrilských písmen, zatímco 22 z celkového počtu zůstává volné.
Aktuální verze aplikace Unicode
S řešením svého primárního úkolu, kterým bylo standardizovat fonty a vytvořit pro ně jediný kódový prostor, konsorcium nezastavilo svou práci. Unicode se neustále vyvíjí a roste. Poslední verze této normy, 9,0, byla vydána v roce 2016. Obsahovalo šest dalších abeced a rozšířilo seznam standardizovaných emodí.
Je třeba poznamenat, že za účelem zjednodušení výzkumu, dokonce i tzv mrtvé jazyky. Dostali toto jméno, protože nejsou žádní lidé, pro které by byli příbuzní. Tato skupina také zahrnuje jazyky, které se dostaly do naší doby pouze ve formě písemných památek.
Ad
V zásadě může každý požádat o přidání znaků do nové specifikace Unicode. Je pravda, že to bude muset zaplnit slušné množství zdrojových dokumentů a strávit spoustu času. Živým příkladem je příběh programátora Terence Edena. V roce 2013 požádal o zahrnutí do specifikace znaků spojených s označením ovládacích tlačítek počítače. V technické dokumentaci byly použity od poloviny 70. let minulého století, ale až do specifikace 9.0 se objevily, nebyly součástí Unicode.
Tabulka symbolů
V každém počítači, bez ohledu na použitý operační systém, se používá tabulka symbolů Unicode. Jak používat tyto tabulky, kde je najít a proč mohou být pro průměrného uživatele užitečné?
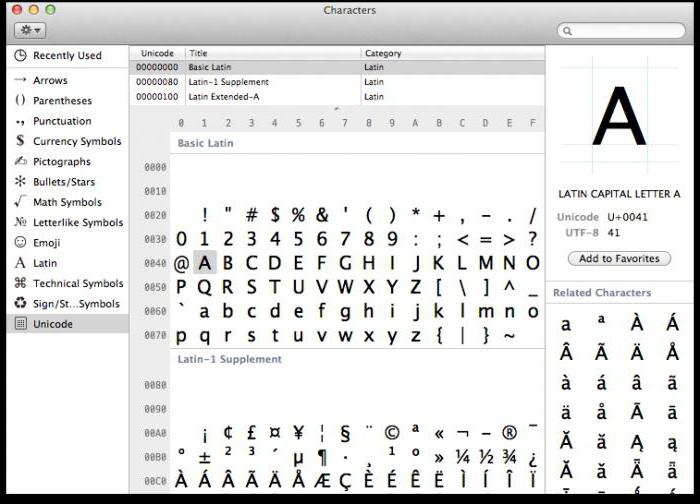
V systému Windows je tabulka symbolů umístěna v nabídce "Nástroje". V linuxové řadě operačních systémů se obvykle nachází v podkapitole Standard a v MacOS v nastavení klávesnice. Hlavním účelem této tabulky je zadávat znaky do textových dokumentů, které nejsou umístěny na klávesnici.
Žádost o tyto tabulky lze nalézt nejširší: od vstupu technických symbolů a ikon národních měnových systémů do písemných pokynů pro praktické uplatnění Tarotových karet.
Na závěr
Unicode se používá všude a vstupuje do našich životů společně s vývojem internetu a mobilních technologií. Díky jeho použití byl systém mezinárodních komunikací výrazně zjednodušen. Můžeme říci, že zavedení Unicode je indikativní, ale zcela nepostřehnutelné z příkladu využití technologie pro společné dobro celého lidstva.